KI ist daher ohne Zweifel in vielen Bereichen auch mit Risiken verbunden. Um diese Risiken einschätzen zu können, betrachten wir zunächst kurz die Techniken, die bei KI zum Einsatz kommen, und untersuchen dann Beispiele für aktuelle Anwendungsbereiche insbesondere in der Informationssicherheit genauer. Es wird sich dabei zwar zeigen, dass KI ausgesprochen erstaunliche Potentiale, jedoch auch höchst interessante Nebenwirkungen haben kann und neue Angriffsvektoren ermöglicht. Daher muss überlegt werden, welche Sicherheitsmaßnahmen hier erforderlich und nach dem aktuellen Stand der Entwicklung auch möglich sind.
1. Grundbegriffe der KI
Im Zusammenhang mit dem Begriff KI fallen immer wieder die Begriffe Maschinelles Lernen, Künstliche Neuronale Netze, Deep Learning und Big Data.
Maschinelles Lernen (ML) bedeutet, dass ein künstliches System aus Beispieldaten ähnlich wie aus Erfahrungen Wissen erlernt und dieses anschließend adaptiv auf andere Eingabedaten anwenden kann. In den Lerndaten werden Muster und Gesetzmäßigkeiten erkannt, die dann auch in unbekannten Daten gefunden werden können. Es handelt sich also um einen selbstadaptiven Algorithmus.
Künstliche Neuronale Netze (KNNs) sind Netze aus künstlichen Neuronen als Modelle für die Informationsverarbeitung. Sie bilden ein Teilgebiet der KI. Die Neuronen sind in verschiedenen Schichten von der Eingabeschicht über verborgene interne Schichten bis zu Ausgabeschicht angeordnet und miteinander über gewichtete Kanten verbunden, so dass der Output eines Neurons als Input für das nächste Neuron dient. Durch eine Trainingsphase werden in Analogie zum menschlichen Nervensystem die Gewichtungen so angepasst (also verstärkt oder abgeschwächt), dass durch vorgegebene Eingaben ein Lernerfolg manifestiert wird.
Deep Learning bezeichnet einen Teilbereich des Maschinellen Lernens. Es werden komplexe KNNs mit mehreren Zwischenschichten (deswegen „deep“) genutzt und große Datenmengen verarbeitet. Im Gegensatz zum reinen Maschinellen Lernen geschieht die Identifikation der Muster und Gesetzmäßigkeiten der Lerndaten nicht durch den Menschen, sondern das KNN sucht durch „Try und Error“ selbstständig nach ihnen.
Big Data nennt man die Suche nach Mustern und Beziehungen in sehr großen komplexen Datenmengen mit den Mitteln KI aber auch der Statistik bzw. Stochastik. Hierbei bezieht sich das Wort „Big“ auf die drei Dimensionen Datenvolumen, Geschwindigkeit, mit der die Datenmengen generiert und transferiert werden sowie Bandbreite der Datentypen und -quellen.
2. Beispiele für Anwendungen von KI
Um die Bandbreite der Anwendungspalette von KI zu illustrieren, werden im Folgenden exemplarisch aus der Vielzahl der Anwendungsbereiche Beispiele herausgegriffen.
Spracherkennung
Spracherkennung ist ein Klassiker der KI. Hier hatten wir ja schon Alexa erwähnt. Sprachanalyse benötigt jedoch Rechenleistung und die interessante Frage ist, wo bei Alexa diese Rechenleistung liegt? Natürlich in der Cloud, wo sonst! Das bedeutet, dass zunächst die an Alexa gerichteten Sprachkommandos über das Internet an die Amazon Cloud geschickt und dort analysiert und ggf. nach einer weiteren Sprachinteraktion mit dem Nutzer auch dort ausgeführt werden (z.B. Bestellungen „Alexa: Bitte bestell meine Lieblingspizza“). Die Ergebnisse können aber auch an das initiierende Gerät, z.B. Amazon Echo-Plus, zurückgeschickt werden und als Kommando lokal ausgeführt werden („Alexa: Mach das Licht im Wohnzimmer an“), wie in Abbildung 1 gezeigt.
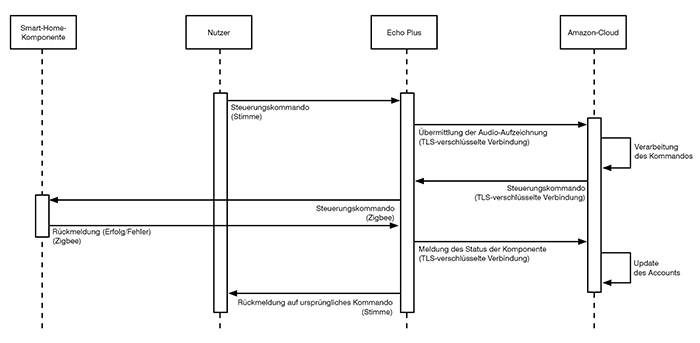
Abbildung 1: Steuerung von Smart-Home-Komponenten über Amazon Echo Plus
Bildverarbeitung
In der Bildverarbeitung ist KI ebenfalls stark präsent. Eine Gesichtserkennung per KI kann zur Authentisierung genutzt werden, wie es z.B. mit Face ID am iPhone X geschieht. Autonome Fahrzeuge im Straßenverkehr wären ohne eine Auswertung von Videodaten undenkbar.
Die Augmented Reality basiert darauf, dass etwa auf einem Smartphone reale Bilder der Umgebung zielgerichtet mit Zusatzinformationen versehen werden. Dies ist nicht nur für den Consumer-Bereich (Pokémon GO ist hier ein sehr schönes Beispiel von Augmented Reality) interessant. In der Industrie 4.0 gibt es Anwendungen, in denen Pläne von noch im Bau befindlichen Anlagen in ein Bild eingeblendet werden oder das Bild einer bestehenden Anlage mit Konstruktionsplänen überlagert oder der vermutete Ort einer Fehlermeldung in den Eingeweiden einer Anlage eingeblendet wird.
Auch in der Medizin zeigt sich das Potential von KI etwa in der Telemedizin bei der Analyse von Patientenverhalten in einer Videokonferenz oder bei der Bildanalyse zur Hautkrebserkennung.
Videokonferenzen / Meeting Solutions
Auch in den Bereichen von Videokonferenzen und Meeting Solutions werden inzwischen KI-basierte Mehrwertdienste eingesetzt. Die Firma Cisco hat hier schon erste Schritte auf ihrem Weg der geplanten fünf Stufen von Sprachrobotern zur Nutzung in Videokonferenzen / Meeting Solutions umgesetzt (siehe https://blogs.cisco.com/news/when-ai-joins-your-meeting). Auch wenn die gesamte geplante Entwicklung noch Jahre benötigt und noch recht futuristisch klingt, so ist doch ein Anfang gemacht. Erste sogenannte Meeting Bots können nach ihrer Aktivierung durch Sprachaufforderungen wie „Join the meeting“ die Einwahl und Anmeldung in Konferenzen übernehmen und der Teilnehmer kann sich auf die eigentliche Konferenz konzentrieren.
Doch diese Bots sollen bald noch mehr können. In Stufe 2 sollen sie der Konferenz in ganz groben Zügen folgen können auf einem Niveau der Art „Wer nimmt an der Konferenz teil, welche Dateien werden genutzt“. Außerdem sollen sie in der Lage sein, sprachliche Befehle wie „Erinnere den Teilnehmer xyz daran, die Präsentation an das Team zu senden“ umzusetzen.
Für Stufe 3 ist geplant, dass die Bots auch semantisch der Konferenz folgen können. Sie sollen einzelne Themen unterscheiden können und eine grobe Zusammenfassung und Analyse der Konferenz erstellen können. Hierfür sollen sie auch firmen- und branchenspezifische Wissensdatenbanken, Fachlexiken und FAQs nutzen können.
Level-4-Bots sollen dann bereits als intelligente Teilnehmer einer Konferenz in diese eingreifen können, indem sie z. B. Hintergrundmaterial wie Veröffentlichungen o. ä. zu einem behandelten Thema liefern. Außerdem sollen sie in einer Konferenz getroffene Vereinbarungen und Ziele erkennen und die Teilnehmer an ihre Einhaltung und Umsetzung erinnern. Besonders interessant ist, dass diese Bots auch nonverbale Kommunikation deuten können sollen.
Während die Bots von Level 4 noch einzelne Teams dabei unterstützen sollen, ihre Ziele umzusetzen, sollen die Bots von Level 5 die Verständigung zwischen diesen Teams verbessern. Ein solcher Bot soll in allen Konferenzen anwesend sein und dadurch Querverbindungen zwischen den einzelnen Teams finden. Dies können überlappende Themen, die Einbeziehung geeigneter Mitarbeiter anderer Teams und ähnliche Aspekte sein. Durch den Inhalt aller Konferenzen und weitere Informationen aus sozialen Firmennetzen wie Chat- und E-Mail-Daten sollen die Level-5-Bots in der Lage sein, die Umsetzung der Firmenziele zu verbessern.
Aber was für Firmen nach einer interessanten Effizienzsteigerung und Verbesserung aussieht, kann für den einzelnen Mitarbeiter auch angsteinflößend sein, wenn es zukünftig Instanzen geben soll, die alles aufzeichnen, korrelieren und protokollieren, was in irgendwelchen Konferenzen, E-Mails und Chats gesagt wird. Der Übergang zu einer totalen Überwachung ist fließend und wie solche Bots konform zur Datenschutz-Grundverordnung (DSGVO) gestaltet und genutzt werden können, ist noch recht unklar.
Software-Entwicklung
Die moderne Softwareentwicklung ist geprägt von immer kürzeren Zyklen der Auslieferung neuer Software Releases. Vor gar nicht allzu langer Zeit wurden Software Releases jährlich, halbjährlich oder quartalsweise ausgeliefert. Mit der agilen Software-Entwicklung hat sich aber inzwischen eine Zykluszeit von zwei Wochen oder sogar weniger etabliert. Natürlich muss die Software in jedem Zyklus getestet werden und bei Zyklen von zwei Wochen oder weniger ergibt sich in der Software-Entwicklung ein Zustand des Continuous Testing. Dies wiederum stellt sehr hohe Anforderungen an die Erzeugung, Auswahl und Parametrierung von Test Cases und erfordert eine kontinuierliche und automatisierte Durchführung der Test Cases.
Spätestens hier findet KI ihren Einzug in die Software-Entwicklung und wird beispielsweise eingesetzt zur Erzeugung von Test Cases [1], d.h. von
- Verhalten, das den normalen menschlichen Nutzer nachbildet (positive Test Cases),
- bösartigem Verhalten bzw. Angriffen (negative Test Cases) und
- dynamischem bzw. selbstlernendem Verhalten, das sich durch Rückkopplung aus dem Verhalten des im Test befindlichen Systems ergibt.
KI wird auch beim Static Application Security Testing (SAST) auf Code-Niveau (Quelltext aber auch Maschinencode) verwendet, um Fehler und Schwachstellen unmittelbar im Code zu finden (siehe z.B. https://dzone.com/articles/the-magic-of-ai-in-static-application-security-tes).
In der Software-Entwicklung werden dann also Maschinen von Maschinen getestet.
Robotik und autonome Systeme
Besonders spannend ist KI, wenn in Echtzeit und gegebenenfalls ohne menschliches Korrektiv auf KI-Basis Handlungen ausgelöst werden, wie dies z. B. bei autonomen (selbstfahrenden) Systemen oder bei Robotern und Maschinen, die mit Menschen interagieren, erforderlich ist. Hier müssen ggf. sogar moralische Entscheidungen durch einen Algorithmus getroffen werden, wenn Situationen entstehen, in denen ein Roboter Personenschäden nicht mehr verhindern und keine eindeutige Entscheidung zur Minimierung des Schadens treffen kann (siehe z.B. http://moralmachine.mit.edu/). Maschinenethik ist in diesem Zusammenhang ein höchst interessantes und kontrovers diskutiertes Forschungsgebiet in der Schnittmenge zwischen Philosophie und Informatik (siehe z.B. http://www.bpb.de/apuz/263684/koennen-und-sollen-maschinen-moralisch-handeln?p=all).
Prognosen
Weiterhin kann eine KI genutzt werden, um Prognosen auf Basis eines Datenmaterials (z.B. Video- und andere Bilddaten, Sensordaten und andere Messwerte) zu stellen. Hier geht es nicht nur um Wettervorhersage oder die Prognose von Staus im Straßenverkehr. Ein höchst interessantes aber auch gefährliches Beispiel, das nicht von ungefähr an Science Fiction erinnert, ist Predictive Policing (siehe z.B. https://www.zeit.de/digital/datenschutz/2017-10/pre-crime-film-predictive-policing). Hier steht unter anderem die Ermittlung der Wahrscheinlichkeiten für Verbrechen und damit die Prognose von potentiellen Tatorten im Vordergrund. KI kann hier aber auch zur Eingrenzung von Tatverdächtigen auf Basis von Big Data dienen. Stellen wir uns nun vor, dass für jeden Mitbürger eine KI ein potentielles Strafregister pflegen und die Wahrscheinlichkeit prognostizieren würde, mit der ein Mitbürger ein gewisses Verbrechen wann und wo begehen könnte, dann hätten wir quasi ein vorhergesagtes polizeiliches Führungszeugnis. Big Brother war gestern, Big KI ist heute.
Eine weniger „explosive“ Variante der KI-Nutzung ist Predictive Maintenance, das ein wichtiger Bestandteil der Industrie 4.0 ist. Bei Predictive Maintenance geht es um die Vorhersage von Maschinenteilausfällen z.B. durch Verschleißerscheinungen und um den vorausschauenden Austausch entsprechender Komponenten, auch wenn diese zum Austauschzeitpunkt noch funktionieren.
3. KI als Werkzeug der Informationssicherheit
Eine entsprechende Vielzahl von Anwendungsfällen der KI gibt es natürlich auch in der Informationssicherheit und KI ist auch hier inzwischen anscheinend ein ganz normales Werkzeug geworden. Eingesetzt wird KI beispielsweise für die automatisierte Klassifikation von Daten für Data Loss Prevention (DLP), für die Erkennung von Malware, Spam- und Phishing-Mails und für die Erkennung von Schwachstellen und Angriffsmustern in Netzwerken, IT-Systemen und Anwendungen.
Automatisierte Klassifikation von Daten für Data Loss Prevention (DLP)
DLP hat das Ziel die Kommunikation von klassifizierten, beispielsweise als streng vertraulich eingestuften Daten zu kontrollieren und ggf. sogar Datenbewegungen zu verhindern.
Die automatisierte Klassifizierung von Dokumenten und allgemein von Daten ist dabei das Kernproblem von DLP, denn eine korrekte Klassifikation ist Grundvoraussetzung für DLP aber niemand möchte natürlich alle seine Daten von Hand klassifizieren müssen. Machine Learning ist hier eine wichtige Schlüsseltechnik, um die Klassifikation zu automatisieren [2]. Dabei wird die KI zunächst mit exemplarischen Dokumenten angelernt, bei denen eine Klassifizierung bereits bekannt ist, um dann in einer Pilotphase immer besser auch bisher unbekannte Dokumente automatisiert klassifizieren zu können.
Erkennung von Malware
Für die Erkennung von Malware sind KI-Techniken seit geraumer Zeit keine Seltenheit mehr. Ein sehr schönes Beispiel liefert hier Windows Defender Advanced Threat Protection (ATP). Hier wird mit Hilfe von KI und dem Einsatz von Cloud-Technik ein mehrstufiger Ansatz genutzt, um auch tiefgehende Analysen von Daten auf Schadsoftware-Befall zu ermöglichen.
Bei ATP verfügt ein Client dabei auch über lokale Modelle des Maschinellen Lernens, die über verhaltensbasierte Erkennungsmechanismen und Heuristiken innerhalb von Millisekunden einen Großteil an Malware erkennen können. In Fällen, wo die lokale KI unsicher ist, kann der Client eine Anfrage in die Cloud senden und die weiteren dort befindlichen Instanzen können aufgrund ihrer weiterreichenden Fähigkeiten eine tiefere Untersuchung durchführen, die allerdings gegebenenfalls auch mehr Zeit beansprucht.
Im Extremfall wird in der Cloud eine potentiell gefährliche Software in einer Sandbox ausgeführt, d.h. kontrolliert zur Explosion gebracht und die Reaktion mit KI-Techniken analysiert. Deswegen werden diese KI-Modelle auch „Detonation-based ML Models“ genannt. Dabei wird beispielsweise von der KI untersucht, welche Zugriffe die Software in der Sandbox versucht und je nach Verhalten wird die Software dann als Schadsoftware eingestuft. Auf diese Weise kann auch eine bisher unbekannte Schadsoftware durch ML erkannt werden. In diesem Fall kann die KI auch in der Schadsoftware nach charakterisierenden Mustern suchen und dann unmittelbar über die Cloud die ATP-Clients mit der aktualisierten Information versorgen, die dann vor der neuen Schadsoftware geschützt sind [3].
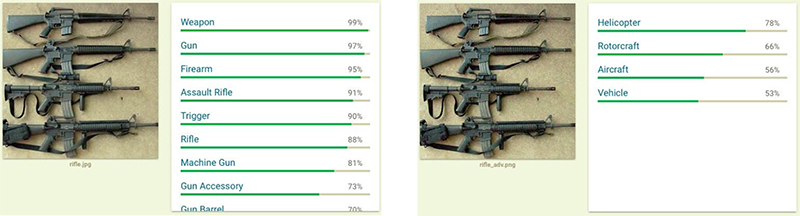
Da eine KI grundsätzlich in der Lage ist, auch in unbekannten Daten Ähnlichkeiten zu bekannten Mustern zu erkennen und mit Wahrscheinlichkeiten zu bewerten, eignet sich eine KI im Virenschutz auch vorzüglich dazu, die typischen Tricks der Entwickler von Schadsoftware zu vereiteln. Die eigentlichen bösartigen Teile einer Schadsoftware werden nämlich oft nicht neu entwickelt, sondern in einer neuen Verpackung wiederverwendet und dabei das Aussehen des Codes geändert, ohne dass sich die eigentliche Funktion ändert. Eine KI kann jedoch unter der Verpackung die Ähnlichkeiten zu bekanntem Schadcode entdecken und der Virenschutz kann die Schadsoftware abwehren.
Erkennung von Spam- und Phishing-Mails
Auch zur Erkennung von Spam- und Phishing-Mails wird KI für die Untersuchung der Reputation der Quelle und von Links in E-Mails sowie für die Untersuchung des Inhalts der Mails, z.B. Suche nach Fehlern bzw. Anomalien im Text, die für Phishing Mails typisch sind, eingesetzt. Außerdem wird auch hier mit Sandboxing gearbeitet. Analog zum Virenschutz erfolgt dabei eine Untersuchung des Verhaltens bei Öffnen eines E-Mail-Anhangs oder bei Anklicken eines Links in einer E-Mail, und an dieser Stelle wird ebenfalls mit KI-Techniken gearbeitet, um ein bösartiges Verhalten zu erkennen.
Erkennung von Angriffsmustern in Netzwerken, IT-Systemen und Anwendungen
Firewalls dienen zur Trennung von unterschiedlichen Vertrauensbereichen und Sicherheitsniveaus in Netzwerken und sind natürlich ein guter Ort, um Angriffe zu erkennen. Nicht ohne Grund hat eine Next Generation Firewall die Möglichkeit per Intrusion Detection & Prevention System (IDPS) den Verkehr auf Angriffsmuster zu analysieren und entsprechend zu reagieren. In der Vergangenheit wurde hier mit Signaturen, mit der Analyse der Abweichung zu Protokollspezifikationen und mit statistischen Analysen gearbeitet. Natürlich haben die Hersteller ihre Firewalls inzwischen um entsprechende KI-Techniken wie Maschinelles Lernen zur Payload-Analyse ergänzt. Ein Beispiel hierzu ist SandBlast Network des Herstellers Check Point.
Natürlich setzt dies voraus, dass der entsprechende Verkehr die Firewall auch durchläuft. Gewisse Angriffe oder Phasen eines Angriffs, die rein intern ablaufen, könnten also auf diese Weise nicht erkannt werden.
Betrachten wir daher einen sogenannten zielgerichteten Angriff (im Englischen Advanced Persistent Threat, kurz APT) etwas genauer [4]. Ein zielgerichteter Angriff hat ein fest umrissenes Angriffsziel, läuft typischerweise in mehreren Phasen ab und kombiniert unterschiedliche, aufeinander aufbauende Angriffstechniken.

Abbildung 2: Ereignisse, die auf einen zielgerichteten Angriff hindeuten könnten
Am Anfang könnten Phishing Mails stehen, die, wenn sie gut konstruiert und von einer vertrauenswürdigen Quelle stammen, das Secure-E-Mail-Gateway der angegriffenen Institution passieren. Wenn nun der Adressat der E-Mail etwa auf einen Link in der Phishing E-Mail klickt, wird vielleicht eine kleine unscheinbare Schadsoftware geladen und ausgeführt. Diese kleine Schadsoftware lädt dann typischerweise den eigentlichen Schädling auf das angegriffene System nach. Hierzu muss lediglich ein Internet-Zugang für das infizierte System erlaubt sein, das dann ein sogenanntes Remote Administration Tool (RAT), sprich einen Trojaner, herunterlädt und ausführt. Das RAT unterhält dann eine Verbindung zur zentralen Infrastruktur des Angreifers, dem Command and Control Server (C&C). Diese Kommunikation ist natürlich nach den Regeln der Kunst so verschleiert, dass eine Nachverfolgung ausgesprochen schwer ist. Über das RAT kann der Angreifer dann zumindest mit den Berechtigungen des Nutzers auf Ressourcen in der IT-Infrastruktur zugreifen. Nicht selten ist aber das zunächst angegriffene System nicht das eigentliche Ziel bzw. nicht das einzige Ziel. Dann erfolgt eine Ausbreitung des Angriffs im Netzwerk, indem Server, weitere PCs z.B. von Administratoren und sonstige Systeme angegriffen werden. Ggf. wird hierfür zusätzliche Schadsoftware vom C&C geladen. Wenn der Angreifer schließlich am Ziel ist, verrichtet der Angreifer seinen Dienst, indem er z.B. Systeme sabotiert oder vertrauliche Dokumente bzw. Daten stiehlt. Die Anzeichen, die auf einen solchen Angriff hindeuten könnten, verteilen sich dabei also system- und anwendungsübergreifend und über einen längeren Zeitraum, wie in Abbildung 2 skizziert.
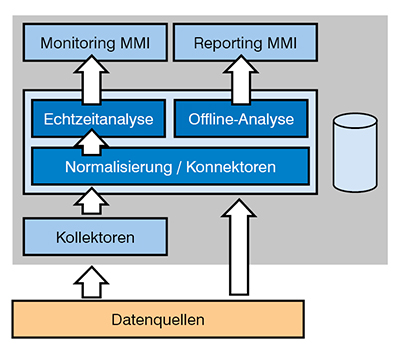
Abbildung 3: Grundsätzliche Architektur eines SIEM
Wir benötigen also ein Werkzeug, das system- und anwendungsübergreifend in der Lage ist, Ereignisse zu erkennen, zu analysieren und insbesondere auch über einen ggf. längeren Zeitraum zu korrelieren. Hierzu dienen Lösungen für das sogenannte Security Information and Event Management (SIEM), die eine Aufzeichnung und Echtzeitanalyse von Ereignissen zur Erkennung und Analyse von Anomalien und Sicherheitsvorfällen ermöglichen (siehe Abbildung 3). SIEM-Systeme greifen hierzu auf unterschiedlichste Informationsquellen, wie System-Logs und Monitoring-Daten, zu. Außerdem können IT-Systeme und Anwendungen aktiv Ereignisse an ein SIEM-System melden. KI ist dabei in SIEM-Lösungen insbesondere zur Ereigniskorrelation mittlerweile ein fester Bestandteil geworden. Dabei kommen meist Maschinelles Lernen und Big Data zum Einsatz. Zur Analyse von Ereignissen werden aber auch Techniken auf Basis von Signaturen und statistischen bzw. stochastischen Modellen genutzt.
4. Kehrseite der Medaille
Doch wie bei allen interessanten Errungenschaften gibt es leider auch bei KI Probleme und Gefahren.
Wenn sich eine KI dazu eignet in Systemen Schwachstellen zu finden, kann eine solche KI natürlich auch als Angriffswerkzeug missbraucht werden. KI als Schadsoftware ist eine höchst interessante Bedrohungsdimension.
Außerdem kann eine KI natürlich auch Fehler machen und falsche oder zumindest überraschende Lösungen finden, denn Software ist nun einmal praktisch nie fehlerfrei. Und das gilt natürlich auch für KI. Ursachen können sein, dass ein Entwickler die Zielsetzung und die Rahmenbedingungen nicht genau genug spezifiziert hat oder beim Anlernen nicht genug oder unzureichend geeignete Daten zur Verfügung standen.
Aber das Kernproblem ist, dass wir in vielen Fällen kaum beurteilen können, wie und warum eine KI gewisse Schlüsse zieht, da sich bei jedem Durchlauf durch eine selbstlernende KI die Komplexität eines entsprechenden Entscheidungsbaums exponentiell vergrößert. Der Entwickler einer ausgesprochen erfolgreichen KI zur Erkennung von psychischen Krankheiten hat hierzu einmal treffend gesagt: „We can build these models, but we don’t know how they work.“ [5]
Im Folgenden betrachten wir ein paar Beispiele, die typische Problembereiche bei KIs illustrieren.